Data Science vs Software Engineering isn’t really a battle. Rather these are two somewhat overlapping and complementary fields that are similar in many ways.
However, dig deeper in the discussion of data science vs software engineering, and you’ll find key differences in the two fields:
- Data science is more exploratory.
- Software engineers are more focused on systems building.
- And data science project management should be more open to changes.
So if you’re looking to enter either field, closely assess these differences to better understand where you’d best fit.

Or if you’re already leading a data science team or project, understand how data science is unique to drive better outcomes.
Data Science vs Software Engineering Fields
What is Data science?
If you ask five data scientists to define data science, you’ll probably get five different answers but they’ll revolve around common concepts. The Wikipedia definition hits on many of these:
Data science is an interdisciplinary field that uses scientific methods, processes, algorithms and systems to extract knowledge and insights from many structural and unstructured data
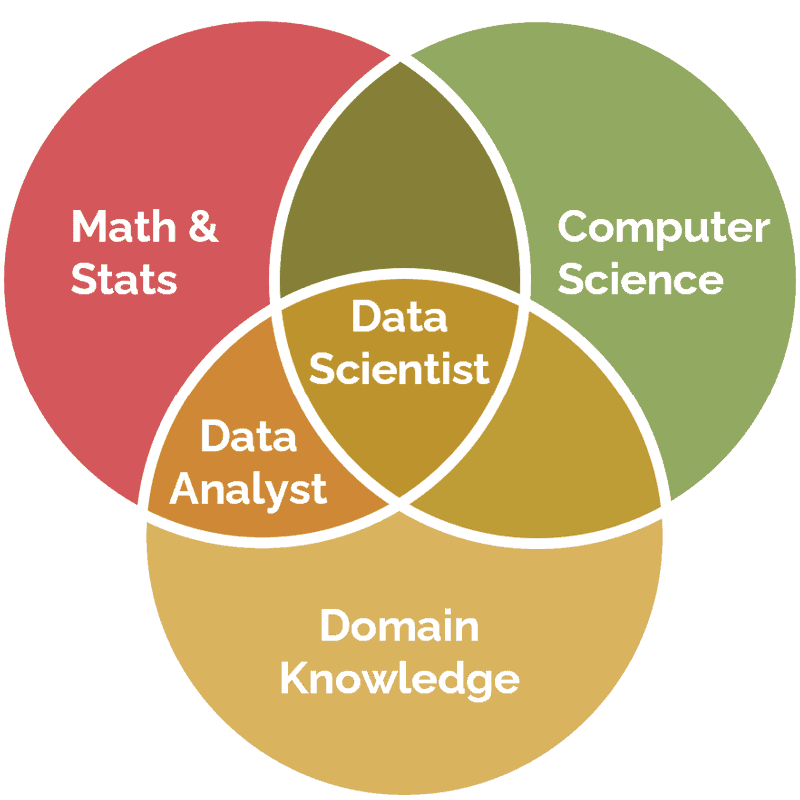
Breaking this apart, data science is interdisciplinary, combining practices from computer science, math and statistics, and domain-specific knowledge. Central to data science workflows and the data science life cycle is the scientific method of asking a question, developing a hypothesis, testing the hypothesis, and analyzing the results. Machine learning algorithms (code with data) and broader software and statistical systems are common tools that data scientists use on their quest to extract meaningful knowledge and insights from structured and unstructured data.
What is Software Engineering?
Software engineering’s definition is more concrete, and the term itself is self-defining:
The application of a systematic, disciplined, quantifiable approach to the development, operation, and maintenance of software; that is, the application of engineering to software
The field is also broad, ranging from the development of the browser you’re using to read this post, to the code behind your favorite video game, and to the embedded software that runs your car’s engine.
How are Data Science and Software Engineering related?
On the surface, these fields are very similar. Both are high-tech fields that are largely built on top of the fields of computer science and mathematics.
Indeed, the distinction between data science and software engineering is partially blending together as organizations are more frequently deploying data science models into larger overarching software systems.
How are Data Science and Software Engineering different?
However, dig deeper, and you’ll also find some stark contrasts between data science and software engineering.
- Age: The field of software engineering is much older, stemming from the 1940s. And, although the concept of data analytical processes stems back centuries, the modern field of data science is much newer. The term “data science” itself didn’t even crop up until the past two decades.
- Organizational Understanding: Related to the prior point, organizations often have less of a clear idea of what is possible from data science and what to expect from their data science teams.
- Establishment: Many complain that “data science” is a buzzword, and Merriam Webster doesn’t even define the term. However, no one questions software engineering’s existence as a distinct field.
- Problem space: Data science focuses on exploration and discovery (such as “finding insight in the data”, and identifying new data sources that can be integrated into predictive models), while software engineering typically focuses on implementing a solution that addresses specific requirements (perhaps defined incrementally).
- Domain Focus: Although both fields rely on data, math, and code, data science emphasizes the data and math while software engineering is more heavily code-oriented.
Data Scientists vs Software Engineers
What is a Data Scientist?
Data scientists collect, reformat, model, and interpret data. While some data scientists have a strong theoretical bent, most data scientists working in for-profit enterprises are pragmatic and use their skills to derive practical information from data. The best are storytellers at heart and use data to inspire organizational action.
Job Titles: Depending on their focus and organization, they might hold titles such as “quantitative analyst” or “machine learning engineer” (someone who focuses on deploying machine learning models). Domain-specific data science-like roles may include “algorithmic trader” “bioinformatics scientist”, or “physicist”.
Common Technical Expertise: Python, R, Python, Hadoop, Apache Spark, Tableau, SQL, Databricks, MatLab, SAS
What is a Software Engineer?
Software engineers write and test software code that meet the needs of end users. Depending on the environment they work in, software engineers might also be responsible for the complete software product life cycle. They might start with the initial analysis of stakeholders needs, provide post-production maintenance to ensure normal functionality, and upgrade software systems to meet the ever-changing needs of the stakeholders.
Job Titles: Software engineering job titles might focus on the software layer ranging from “back end developer” to “front end developer” or both — “full-stack developer”. Or titles might focus on where the code is deployed — “application developer”, “systems engineer”, or “embedded software engineer”.
Common Technical Expertise: C++, Java, object oriented programming, git, PHP, JavaScript, SQL
How are Data Scientists and Software Engineers similar?
Successful data scientists and software engineers have a lot in common. Both:
- Are creative and analytical problem solvers who design complex systems
- Work in rapidly growing and well-paid professions
- Will constantly be learning to keep abreast of the latest industry trends
- Have solid attention to detail and a lot of patience to troubleshoot pernicious problems
Job Rankings: Both fields rank among the best jobs in terms of salary and job satisfaction. In fact, six of the seven best jobs per 2020’s Glassdoor rankings are data science or software engineering related:
| Rank | Job Title | Median Base Salary | Job Satisfaction | Job Openings |
|---|---|---|---|---|
| 1 | Front End Engineer | $105,240 | 3.9/5 | 13,122 |
| 2 | Java Developer | $83,589 | 3.9/5 | 16,136 |
| 3 | Data Scientist | $107,801 | 4.0/5 | 6,542 |
| 4 | Product Manager | $117,713 | 3.8/5 | 12,173 |
| 5 | DevOps Engineer | $107,310 | 3.9/5 | 6,603 |
| 6 | Data Engineer | $102,472 | 3.9/5 | 6,941 |
| 7 | Software Engineer | $105,563 | 3.6/5 | 50,438 |
Source: Glassdoor, 2020
Education: Employers generally expect college degrees for either role with at least a bachelor’s degree for software roles and more advanced degrees for data science roles. Professionals making career transitions into either field often go through data science or coding bootcamps.
However, degrees are not always required as many software engineers and data scientists are self-taught and secure jobs through merit as opposed to credentials. This is unique when compared to other technical professions with six-figure salaries. For example, you probably don’t care about the education of those who developed the routing algorithms and interfaces for your ride-sharing app but you wouldn’t want to jump in an airplane designed by people without a formal education in mechanical or aeronautical engineering.
How are Data Scientists and Software Engineers different?
Prevalence: Software engineers are much more common. Software engineering openings outnumber data scientists openings by about 8-to-1 in the above table.
Skillsets: Data scientists generally need stronger mathematics and statistics backgrounds than their software counterparts. Meanwhile, software engineers usually are better at writing clean production code and understanding how broad systems components fit together.
Experimentation: Moreover, data scientists tend to possess a stronger desire for experimentation and discovery for the unknown while software engineers tend to prefer building stable systems based on what is already known.
Ambiguity: However, the biggest difference between data scientists and software engineers is more conceptual in that data scientists need to be comfortable dealing with ambiguity. Whereas a software engineer is trained to develop systems with definitive logic (e.g. Waive the airfare change fee if and only if the account holder is of platinum status), a data scientist thinks in probabilities (e.g. An account holder with attributes X, Y, and Z is likely to purchase an Economy Comfort upgrade).
Uncertainty is the absolute enemy of the software engineer, yet uncertainty is inevitable in data science
Data Science vs Software Engineering Projects
By definition, both software engineering and data science projects are, well, projects:
Project(n) – a temporary endeavor undertaken to create a unique product, service or result
How are Data Science and Software Projects similar?
Start: Like all good projects, software engineering and data science projects both start with a solid understanding of the underlying problem identification; have a middle execution phase; and have an end.
Commissioning: The administrative project commissioning is highly dependent on the organization but a typical approach for either project type at mid- to large- companies begins with a business stakeholder request for a project. Then, the project team or executive management above the project team approves the project, often issuing a formal project charter to authorize work.
Scope: The objective for either data science or software engineering projects can be narrow-focused to deliver a specific component or comprehensive to deliver an entire solution. Software projects typically fall in this latter bucket. Data science projects are likewise increasingly becoming more comprehensive in scope to include the full value delivery system up through deployment and integration with other systems. This confounds the classification of the project. Is the data exploration and modeling portion the data science project within the over-arching software delivery project or is the overall project lifecycle the data science project? The answer mostly depends on the organizational structure.
Failures: Unfortunately, both software engineering and data science projects have notoriously high failure rates with up to 75% of software projects failing (Geneca, 2017) and 87% of data science projects never making it to production (Venturebeat, 2019).

Software Development Lifecycle
Methodologies and Tools: Project methodologies and project/product management tools for both traditional and agile methodologies are well-established in software. Traditional waterfall approaches leverage elegant Gantt charts with well-defined timelines often managed in a tool like Microsoft Project. Meanwhile, teams leveraging popular agile frameworks such as Scrum, eXtreme Programming, and Kanban tend to place a stronger emphasis on product backlog management in tools like Rally or Jira.
How are Data Science Projects managed?
Meanwhile, the traditional and most popular life cycle model for data science (CRISP-DM) has six phases.
Waterfall vs Agile: A strict interpretation of CRISP-DM with thorough upfront planning and heavy documentation will result in a rigid, waterfall process. However, teams can achieve agility by looping through the entire data science lifecycle multiple times throughout a project.
How are Software Projects managed?
Software engineering projects flow through the software development lifecycle (SDLC) which is often represented with five or six phases.
Waterfall: In traditional software projects, each phase is distinct whereby each phase has to complete before moving onto the subsequent phase. For example, the project starts by comprehensively planning out most (or even all) the work before designing the solution. Moreover, the project ends with the team delivering the whole system in one big bang in the deployment phase.
Agile: However, over the past two decades, software engineering teams have started to favor more flexible approaches whereby each phase overlaps with the next. In agile development, teams rapidly go through several complete mini-product development lifecycles to provide multiple deliverables throughout the broader project lifecycle.

Low Project Maturity: Bear in mind that like the SDLC, CRISP-DM is a process model that explains the steps necessary to deliver a project but does not include broader project management considerations.
And, as a young field, the data science industry has been slow to develop and adopt repeatable, comprehensive data science project management frameworks. For example, while the software project manager position is commonplace, the concept of the data science project manager is just emerging. Consequently, teams often suffer from low project maturity without continuous improvements, well-defined processes, check-points, or frequent feedback.
Data scientists seem to be aware of these issues. Per a 2018 Big Data Conference survey, 85% of data scientists think that adopting an improved process would improve results.
Can you manage Data Science Projects as Software Projects?
Given the similarities between the fields, many organizations counter low data science project maturity by managing them as software projects. However, this is not ideal as data science projects are fundamentally different from software engineering projects.
Data Science vs Software Engineering – Exploring Projects
| Software Engineering | Data Science | |
|---|---|---|
| Project Feasibility | Generally known upfront whether a project is executable | Might not be known until late project phases |
| Focus | Delivering functioning software systems | Delivering actionable insights |
| Longest Phase | Development (coding) | Data preparation |
| Scope | Largely defined by stakeholders and product managers | Somewhat define-able by stakeholders and product managers but also needs to be uncovered based on what the data scientists discover |
| Task Estimation | Task completion time is generally estimate-able | The time required to deliver many steps are unknown |
| Progress Tracking | Somewhat definitive through metrics like number of features or story points complete | More ambiguous. Example: Being 50% done with a model doesn’t mean anything. |
| Knowing it works | Mostly binary. Software either works per the specifications or it does not (e.g. the user interface loads or it doesn’t) | Many shades of gray. Given a model, one person can say it is working and another could say it is not. Both can be right given their frame of reference. |
Given these differences, managing data science projects as traditional software projects will significantly hamper flexibility and short-circuit exploration. Managing them as agile software projects, while certainly better, will also likely fall short as data scientists disdain providing work-size estimates; stakeholders will not have accurate insight into project progress; and team morale may suffer as data scientists may feel that they are being shoe-horned to work in a process foreign to their training.
So how should I manage Data Science Projects?
There’s no straight-forward answer but some (not necessarily mutually exclusive) framework options include:
- Ad Hoc: Go without a defined project management approach. However, this is becoming less viable as data science teams are becoming more team-focused.
- Scrum: Implement software’s most popular agile approach — ideally, without the software-specific tactics that most teams add to the framework. However, the biggest challenge will be dealing with fixed-length iterations.
- Kanban: Given Kanban’s flexibility, it is well-suited for fluid projects that are common in data science. Layer in additional project management approaches for best results.
- R&D: Split your project into research phases that allow for flexible experimentation and development phases focused on engineering workflows.
- TDSP: Adopt the Microsoft Team Data Science Process which combines places an agile wrapper around a CRISP-DM-like lifecycle.
- DDS: Use Data Driven Scrum which is a Scrum-inspired framework with flexible-length iterations and a stronger focus on experimentation.
- Design your own process: Each team and project is unique and each new major framework has to start somewhere. So experiment with what makes sense for your team (and contact us to let us know how it went).
Conclusion
In comparing Data Science vs Software Engineering, you’ll find a lot of similarities. For either field – and especially for data science – start with strong communication about the business need and possible data driven solutions.
Learn More
So we’ve scratched the surface of data science vs software engineering (or how data science projects are different from software projects). To dive deeper on this and broader topics, explore:
Team Management Posts: This post is part of the series which includes posts where you can:
- Discover How to Lead Data Science Teams
- Learn about the 8 Key Roles for Data Science Team
- Understand the difference between Data Science and Software Engineering
- Assess 10 Ethical Questions to ensure you comply
- Explore how to apply CRISP-DM for Teams
- Get 5 Tips for Remote Data Science Teams
- Review Lessons from 20 Data Science Teams
- Know the pros and cons of Centralized vs Decentralized Teams