A machine learning life cycle describes the steps a team (or person) should use to create a predictive machine learning model.
Hence, an ML life cycle is a key part of most data science projects. In fact, for many people, it’s not clear what is the difference between a machine learning life cycle and a data science life cycle.
So, in this post, I’ll explore the machine learning life cycle and discuss how it relates to the data science life cycle.

What is a Life Cycle?
A life cycle is used to explain the steps (or phases) of a project. In short, a team that uses a life cycle will have a consistent vocabulary to describe the work that need to be done.
While machine learning engineers and data scientists can typically describe the steps within a project, they might not use the same words, or even define the same number of phases. By having a consistent vocabulary, the team can better ensure they do not “miss a step”. While you might think that experienced team members would know the steps and not skip steps, teams can easily skip steps. For example, I have often seen that when the team has deadlines, the team finishes one model and then goes directly to trying to create a different model, without really exploring how well the first model performs. This could be due to very tight schedules, or the team’s desire to explore many models and “play with the data”.
There is another benefit to use an ML life cycle, beyond ensuring the team does not miss a step and having a consistent vocabulary. That other benefit is that non-technical people, such as a product owner or a senior manager, can better understand the work required and how for a long the project is towards completion.
In summary, a life cycle framework will:
- Standardize the process and vocabulary
- Help guide the team’s work
- Allow others to understand how a problem is being approached
- Encourage the team to be more thorough, increasing the value of the work.
A Typical Machine Learning Life Cycle
There are many published machine learning life cycles, as well as some machine learning life cycles that are really data science life cycles.
But one of the most popular frameworks is a simple machine learning life cycle known as OSEMN. OSEMN was defined in 2010 by Hilary Mason and Chris Wiggins. OSEMN stands for Obtain, Scrum, Explore, Model, iNterpret. While the original description was on a website that no longer exists, there are many others have that noted the use of OSEMN, such as this older post.
In short, OSEMN’s five phases are described below:

1. Obtain Data
This phase focuses on gathering data from relevant sources. It is also the phase where the team should be thinking of challenges such as how to automate data collection (if needed).
2. Scrub Data
Scrubbing the data, sometimes known as “munging the data” is required because the data obtained in step 1 is typically “messy”. For example, the data might have missing values. This is often the most time-consuming phase of a machine learning project.
3. Explore Data
Exploratory analysis is useful to get a basic understanding of the data. For example, histograms and scatter plots can easily show distributions of the data across various attributes.
4. Model Data
Building a predictive model is typically what people think about when the envision a machine learning project. Note that sometimes the team just needs to build a “good enough” model, not the best model possible.
5. Interpret Results
No model is perfect, and so, people need to understand the predictive power of the model. In addition, this is the phase were the team needs to explore potential bias in the model.
Reframing the Machine Learning Life Cycle
In reviewing OSEMN, one can think of the first three steps as part of data engineering (the tasks required to get, clean and inspect the data), and the last two steps could be considered part of Modeling engineering (the tasks required to build and evaluate the predictive model). This simple two-phase data science life cycle is shown and explained below.

- Data Engineering – The data engineering phase is focused on designing and building data pipelines. These pipelines get, clean and transform data into a format that is more easily used to build a predictive mode. Note that this data might be coming from multiple data sources, so merging the data is also a key aspect of data engineering. This is often where the most time is spent in an ML project, and in fact, many people are hired explicitly to do data engineering (it is a subfield of data science / machine learning).
- Model Engineering – This is the phase that most people associate with building a machine learning model. During this phase, data is used to train and evaluate the model. This is often an iterative task, where the different models are tried, and the model is tuned.
The Data Science Life Cycle
CRISP-DM is the most commonly known and used data science life cycle. So, let’s explore CRISP-DM.
CRISP-DM has 6 phases:
- Business understanding – What does the business need?
- Data understanding – What data do we have / need? Is it clean?
- Data preparation – How do we organize the data for modeling?
- Modeling – What modeling techniques should we apply?
- Evaluation – Which model best meets the business objectives?
- Deployment – How do stakeholders access the results?
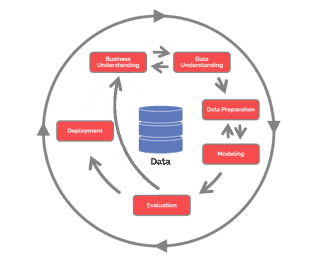
Comparing a Data Science and Machine Learning Life Cycle
At a high level, we can see that the data science life cycle includes all the concepts covered in the machine learning life cycle. However, the data science life cycle includes additional areas of focus that many machine learning life cycles do not cover. Specifically, the data science life cycle covers the end-to-end steps of a project (such as understanding the business context at the start of the project and thinking about deployment towards the end of the project).
For example, in comparing CRISP-DM to OSEMN, the CRISP-DM phrases that map to OSEMN include Data Preparation, Modeling, and Evaluation. But, CRISP-DM has additional phases, such as understanding the business understanding phase, as well as phases at the end of the life cycle, such as Deployment.
Updating the Machine Learning Life Cycle
We can extend this life cycle, to include doing some work at the start of the project to make sure the problem is well understood, and then having a phase at the end of the life cycle to actually put the model into production and monitor the model in production (typically known as Machine Learning Operations or MLOps).
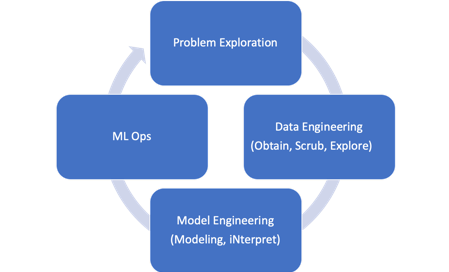
In this expanded machine learning life cycle, the two new phases are:
- Problem exploration – this phase focuses on how the model will be used, what is the desired accuracy of the model, and exploring other details, such as if false positives are worse than false negatives. This phase also includes understanding what data might be available.
- ML Ops (Machine Learning Operations) – this phase is focused on putting the model into production, and then, monitoring the output of the model. This phase also includes maintaining the model (explore ML Ops in more detail).
Comparing CRISP-DM to the Updated Machine Learning Life Cycle
The expanded machine learning life cycle now includes all the data science phases but within a more specific context.
As shown in the updated diagram, the adapted machine learning life cycle includes all the phases that are defined in CRISP-DM, but using terminology more commonly used by data scientists working machine learning projects.

In summary, the updated machine learning life cycle easily maps back to CRISP-DM:
- Problem Exploration: represents both the business understanding and the data understanding CRISP-DM phases
- Data Engineering: represents the CRISP-DM data preparation phase
- Model Engineering: represents the CRISP-DM modeling phase
- ML Ops: represents CRISP-DM the deployment phase
For more information on Using a Machine Learning Life Cycle
Explore posts that provide:
- A discussion on Machine Learning Project Management
- A general overview of the Data Science Life Cycle
- A review of CRISP-DM and CRISP-DMs popularity
Or, for a deeper dive, take one of DSPA’s courses on data science (and machine learning) project management…
Get our Brochure
Get Training from the Organization that Defined Data Driven Scrum






