By their nature, data science products are risky. Building a Data Science MVP can reduce that risk by focusing the early development life cycle on discovery and learning.
The onset of a data science project has a lot of unknowns – on the data, algorithm, systems, and business side. You could naively guess these unknowns upfront and set out to build a full-fledged data science product.
While dreaming big is good. Starting big is risky. Rather, acknowledge that unknowns are, well – unknown. And, instead of trying to model and engineer a full-fledged solution upfront, first focus on learning as much as possible about the problem-solution space. Building a Data Science MVP is a key step in this discovery process.
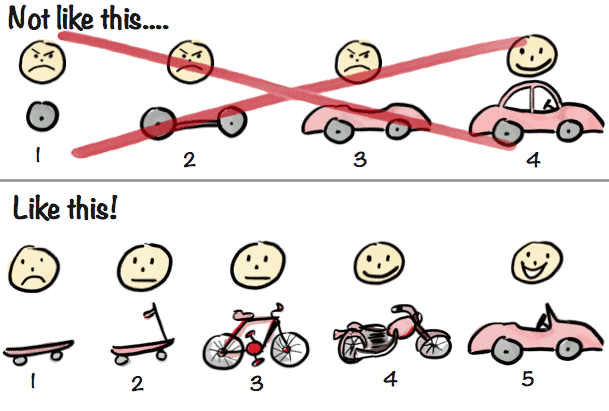
So let’s unravel this by exploring:
- What is an MVP?
- What is an MVP in Data Science?
- How do you build a Data Science MVP?
- Where can you learn more?
What is an MVP?
Product Development for Stable Systems
If you know what is needed and how to deliver it, then you can accurately pre-plan your work. You can request and acquire a budget that should precisely cover your costs. You can order the specific resources needed for the job. And, you can schedule the project team members well in advance. To a large degree, you can build a detailed plan and measure your progress against that plan. In short, you:
“Plan your work. And work your plan.”
My former operations Manager loved this quote
For stable systems with a lot of knowns – like construction management, mature operations, and (arguably) some technology projects – this process works well.
A New Approach – The MVP
A specific artifact to help you accomplish this is the Minimal Viable Product (MVP). Eric Ries popularized this concept in his 2011 book, The Lean Startup:
“The minimum viable product is that version of a new product which allows a team to collect the maximum amount of validated learning about customers with the least effort.”
ERIC RIES
The MVP does not meet all (or even most) of the stakeholder needs. However, it should provide enough functionality with sufficient quality to engage and learn from consumers. And if it doesn’t, then that’s a sign that your initial concept for the product is likely flawed. In that case, you should tweak that concept, pivot toward a new approach, or even cut your losses to re-focus on a different initiative.
The product management field (and specifically software product management) has largely accepted the MVP approach as a best practice. It is also picking up steam in the data science field.
What is an MVP in Data Science?
Realities of Data Science Product Development
Data science projects are a far cry from something like construction that was previously discussed. At the start of a project, you do not fully understand the problem or opportunity. And even if you do, you cannot accurately define the data, algorithm, and infrastructure needed to solve that problem.

Don’t get me wrong – You should define as much as you reasonably can upfront. Most crucially define your goals and how you will measure them (Related: 10 Questions to ask before starting a Data Science Project). However, accept the reality that your initial assumptions are flawed. And shift your mindset away from delivering a full-fledged solution to instead building an initial functional system that meets at least one of the most pressing stakeholder needs. Just as importantly, ensure that you’re ready to learn from this initial system and adjust your plans according to feedback.
An MVP Definition for Data Science
I took Ries’ definition and customized it for data science.
“A data science minimum viable product is that version of a new product which allows a team to collect the maximum amount of validated learning about the real-world model performance and impact with the least effort.”
Let’s break down some of the less obvious concepts in this definition. Specifically “A data science minimum viable product is that version of a new 1) data science product which allows a team to collect the maximum amount of 2) validated learning about the 3) real-world model performance and impact with the 4) least effort.
1. Data Science Product
A data science product is a system, analysis or model that provides insight from data. It’s a broad concept that spans from fully productized systems to a more basic analysis that lack extensive functionality. Examples include:
- A real-time API that an application calls to get recommendations for the next show to watch
- A batch job process that runs overnight to classify which medical images contain a cancerous tumor
- A dashboard and its backend system that outputs the likelihood of customers churning
- A python script that can be manually run to predict next week’s sales
2. Validated Learning
Don’t just get a “head nod” from a product demo. Rather, observe how the product output impacts broader systems. If possible, you should accomplish this scientifically – by running experiments to isolate the impact of the product on the end system or customer.
This concept neatly matches with data scientists’ training to learn via the scientific method. It is also at the core of the Analyze phase of Data Driven Scrum’s Create-Observe-Analyze framework.
A great example would be to deploy your model with an A/B test. Perhaps half of your customers are presented with recommendations based on a heuristic while the other half are presented with recommendations based on the output of an ML model. From there, you can measure whether the ML model-based recommendations outperform the heuristic recommendations based on pre-defined measurement criteria.
3. Real-World Model Performance and Impact
Real-World: The definition explicitly calls out “real-world” to differentiate it from “offline” or “lab” validation. While backtesting a model on historical data is often a key step in the machine learning development life cycle, performance on historical data does not necessarily translate to performance on real-world systems. Therefore, an MVP should be put out in the “wild” to see how it performs with real systems and people.
Performance: These include standard model performance metrics such as recall, precision, RMSE, or MAPE. However, you might also want to look at broader performance metrics like system uptime, model response time, or compute resources used. For an MVP, you shouldn’t care about everything. Rather, identify the most important metrics to measure at the early stage of the development life cycle. Read this post on 10 Data Science Project Metrics to learn more.
Impact: A model that performs well on technical metrics might not advance the business goals. Therefore, look at the underlying goal that you are looking to achieve. For example, a churn prediction model might technically perform well by identifying 5,000 customers who will churn in the next month with a 50% precision. But if the organization is unable to reduce the churn of these at-risk customers, then you need to re-assess your approach.
4. Least Effort
You can measure effort in various ways:
- Time: Consider not just the time of the data scientists, but also the deployment engineers, business stakeholders, and product team.
- Risk: Models have some downside risk. Build an MVP in such a way to minimize the probability and the cost of negative risks. If you cannot “safely” deliver the MVP, consider a more robust MVP – or even a more traditional product development approach.
- Cost: If it’s a heavy model (which you should avoid for an MVP if possible), you might also want to track the use of compute resources or the marginal cost of additional licenses. However, Time and Risk are usually more important factors in data science.
Don’t Miss Out on the Latest
Sign up for the Data Science Project Manager’s Tips to learn 4 differentiating factors to better manage data science projects. Plus, you’ll get monthly updates on the latest articles, research, and offers.
How do you Build a Data Science MVP?
The Process to Build a Data Science MVP
Build a data science project roadmap to think through and communicate your approach. The MVP should be one step in the roadmap. Your series of deliverables might look something like:
| Phase | Example Deliverable |
|---|---|
| Proof of Concept | Quickly demonstrate the ability to produce a model that performs better than the baseline (“status quo”) performance on backtested data. Usually minimal or no QA and or supporting systems. Often run out of a Python Notebook. |
| Prototype | A more robust model Model has been peer-reviewed. The business has agreed that the model looks promising. Compliance has agreed to proceed to Pilot. |
| MVP Pilot | Build the minimal supporting systems around the model. Consider sticking with a one-time file delivery and manual upload to the target system if the use case allows. Or build a minimally sufficient data pipeline. Set up a measurement approach such as an A/B test to see whether the business target variable improves over the current baseline system on a small subset of customers. |
| Productize MVP | Build a more mature data pipeline. Add monitoring, alerting, and fail-over systems. Refactor code to run more efficiently. Pending the use case, schedule the model to run on a given cadence or API. Deploy the model on a broader set of users (with an ongoing small holdout group) |
| Expand Product | Improve the model performance by adding in new data sets and testing new algorithms. Extend the model to impact broader use cases. Monitor the model in production. Retrain as necessary. |
How Big Should your Data Science MVP Be?
Answer – Smaller than you think. As a guest speaker at Stanford University, Eric Ries explained:
I’m not exaggerating. So the easy formula for finding out what the Minimum Viable Product is taking what you think it is right now and cut it in half and do that two more times and ship that.
Eric Ries
How Can I De-Scope an MVP in Data Science?
Per Ries’ advice, remove any functionality that is not necessary to learn whether or not your plan is correct. That can be a challenge, especially as this might seem counter to your desire to deliver a phenomenal product. But remember, the MVP mindset is not about having the “best” product as an initial release. Rather your focus is on learning what the “best” product should be.
Here are some questions to help you de-scope the business problem, model, and system deployed.
Business Problem
- What is the smallest subset of the overall problem that I could model while still getting enough feedback to validate my learning?
- Get creative – Can you “fake” the existence of a model using a “Wizard of Oz” MVP approach?
Modeling
- What is the simplest algorithm that will provide better performance than today’s baseline performance? Try that first, and move to more sophisticated approaches only if necessary.
- Do I even need a machine learning model? Would a heuristic (or set of logical business rules) perform well enough to provide incremental value to the business?
- If I need to train a model, what is the minimal set of data (number of records, tables, etc) that I need?
Deployment
- What is the simplest deployment mechanism?
- Can this work as a batch model (instead of real-time)?
- Or even more simply, can I just provide the model output as a one-time .csv?
- Instead of setting up automated monitoring and alerting systems, can I manually check the results?
Caution: Don’t Oversimplify
But don’t de-scope too much.
If you oversimplify, you might not be able to learn from the product. Specifically on the data side – don’t take this as an excuse to skip out on quality. With data, “garbage in = garbage out”. In short, question the necessity of each proposed component or step of the MVP. But don’t strip out so much that it doesn’t work.
More importantly, ensure that your MVP will not cause significant harm. This judgment is highly circumstantial to the type of system. For example, a marketing department can accept the risk that an MVP ad optimization system might decrease marketing spend efficiency. However, a bank should not accept the risk that its MVP loan decisioning system might discriminate against protected classes of people. Maintain a high level of data science ethics – even for the MVP.
Where Can You Learn More?
- The MVP Mindset is embedded in the world of Agile.
- Likewise, the MVP concept is widely acknowledged as a best practice in the Product Management field.
- Moreover, the MVP is a step in the overall Data Science Life Cycle.
- Building a Data Science MVP shares many characteristics of a Software MVP. But these are distinct fields. Learn more about the differences between Data Science and Software Engineering.
- Many of these concepts stem from Eric Ries and his Lean Startup movement.
- The Data Science Team Lead courses emphasize approaches to deliver incremental products and an MVP.
Get Training from the Organization that Defined Data Driven Scrum






