Given Scrum’s popularity with software teams, it’s no surprise that many organizations are turning to Scrum for data science product development.
But, Does Scrum work for Data Science?
Well…results vary.
So we’ll start by defining Scrum, then identify Scrum’s use in data science, evaluate its pros and cons, and finally dive into some alternatives like Kanban or Data Driven Scrum.
Scrum Training for Data Science Teams
Scrum is just one of the collaboration frameworks to help manage your data science processes. Take a deep dive into Scrum as well as other frameworks in the Data Science Team Lead course.
What is Scrum?
Founded in the 1990s, Scrum has become the de facto Agile framework, so much so that Agile and Scrum are synonymous in the minds of several professionals.
Although heavily adopted in software, Scrum is also used across a wide variety of other industries. National Public Radio uses it to create new programming, John Deere for new machinery development, Saab for fighter jets, and C.H. Robinson applies Scrum for human resources (Rigby, Sutherland, & Takeuchi, 2016).
The Scrum Guide is the definitive guide to Scrum and defines pillars, values, roles, events, and artifacts. We’ll go into each of these before looking into Scrum’s use in data science.
Scrum Pillars and Values
Scrum’s value system is perhaps the most overlooked part of the Guide. Scrum defines three pillars:
- Transparency: Make emergent work visible.
- Inspection: Look out for variances.
- Adaption: Adapt your processes to minimize adverse variances and maximize beneficial opportunities.
Likewise, Scrum encourages people to likewise adopt and develop five values: commitment, focus, openness, respect, and courage.
Scrum Roles
Scrum recommends teams of up to ten members who collectively have all the capabilities to deliver the product (i.e. they’re full-stack). There are three roles:
- Product Owner: Sets product vision and defines the potential product. increments.
- Scrum Master: Facilitates the Scrum process as a servant leader.
- Development Team: Delivers product increments. For a data science Scrum team, these roles could include data scientists, data engineers, data analysts, systems analysts, and software engineers.
One person could serve multiple roles; however, each role is needed. Yet, the data science scrum master role is often missing from many teams.
Scrum Events
Scrum defines five events, the first of which is a container for all other events.
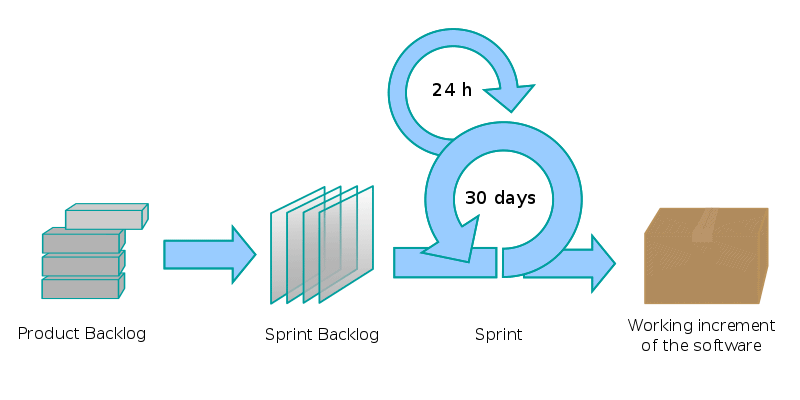
- Sprint: Scrum divides the larger project into a series of mini-projects, each of a consistent and fixed-length up to one month in length. Each mini-project cycle is called a sprint.
- Sprint Planning: A sprint starts with sprint planning. First, the product owner explains the top Backlog Items (features). Then, the development team forecasts what they can deliver by the end of the sprint and makes an actionable sprint plan.
- Daily Scrum (Standup): During the sprint, the team closely coordinates and develops daily plans at daily scrums.
- Sprint Review: At the end of the sprint, the team demonstrates the increments to stakeholders and solicit feedback during sprint review. These increments should be potentially releasable and meet the pre-defined definition of done.
- Sprint Retrospective: To close a sprint, the team reflects and plans for how it can improve in the next sprint during the sprint retrospective.
Scrum Artifacts
Scrum also defines three artifacts:
- Product Backlog: The ordered set of deliverable ideas which helps the product get closer to its Product Goal.
- Sprint Backlog: This contains the Sprint Goal, the selection of backlog items to hit the goal, and an implementation plan.
- Increment: The set of items delivered in the sprint.
Common Scrum Practices
Scrum intentionally leaves out the definition for a full-fledged process and encourages teams to augment the base Scrum framework with their own approaches. Some of the most common are:
- User Stories: Product Owners typically define Backlog Items in the form of a user story. A format flows like: “As user X, I would like Y, so that I can do Z.”
- Story Pointing: Developers often estimate the effort of a user story using story point estimates. These are often scaled in Fibonacci numbers or in T-Shirt sizes (XS, S, M, L, XL).
- Burn-down Charts: This chart shows the team’s progress toward completing the Sprint Commitment with time (in days) on the x-axis and the number of remaining story points on the y-axis.
- Scrum of Scrums: Organizations often host higher-level Daily Scrums whereby the Product Owners or Scrum Masters from across teams coordinate inter-team matters.
Remember, contrary to popular misconceptions, these are augmented practices which are not required for Scrum.
Become a Data Science Team Lead
Master the skills and gain the confidence to deliver data science projects and to lead data teams. Grow with the Data Science Process Alliance’s consulting and certification programs.
Scrum for Data Science
Is Scrum used for Data Science?
Yes. In our 2020 survey, Scrum was the second most selected process.
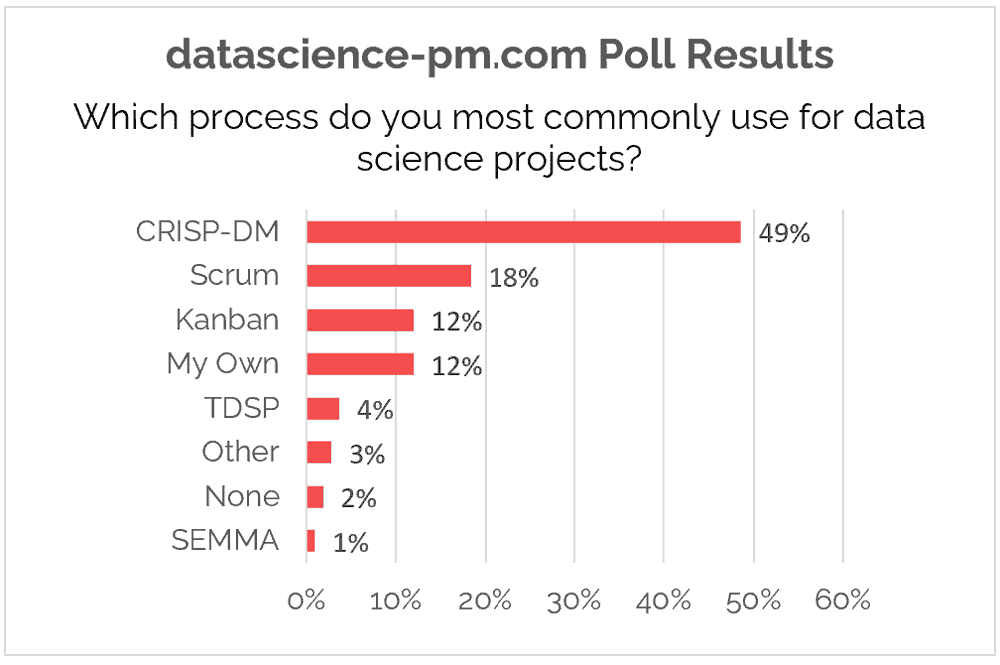
Note that Scrum is not mutually exclusive with any of these above processes. Indeed, most Scrum development teams use a Kanban board for managing their Sprint Backlog. Moreover, data science teams often combine Scrum with a data science life cycle like CRISP-DM, TDSP, or SEMMA.
Although Scrum was the second most selected framework, most data science teams that “use” Scrum, often deviate from the framework. Indeed, we’ve spoken with data science teams that report using Scrum but don’t have a data science Scrum Master, commonly skip out of some of the ceremonies (most notably Sprint Reviews and Retrospectives), or overall don’t seem to follow the Scrum Values.
Do Data Science Teams like Scrum?
Answers are mixed and run the gamut from people loving it to hating it.
One positive example of Scrum comes from Silicon Valley Data Science which was a leading agile consultancy in the San Francisco Bay Area. Watch this 2015 video where John Akred describes his Scrum journey on a prediction project.

However, Scrum detractors seem to outnumber promoters in data science.
Indeed, we’ve only observed a few data science teams that respond positively to Scrum. Many actually resent using it but still try. One project manager we interviewed seems to sum up a collective feeling in stating that: “I don’t know of anything better to use.” Others use it because they are part of a broader (typically IT) organization that encourages or even forces all its teams to use it – often under the common misconception that data science is just like software development.
Here’s a small set of additional grievances on Scrum for data science:
- Why Scrum is Awful for Data Science
- Most responses on this Quora Forum
- Why Data Science Doesn’t Respond Well to Agile
Should you use Scrum for Data Science?
Regardless, an effective Scrum implementation can enable a lot of great practices for data science teams. Let’s review several of these.
Benefits of using Scrum for Data Science
- Empirical Evidence: Like data science, Scrum is founded on the principle of execution based on what is known. Simply put, deliver something. See what works. See what doesn’t work. Adjust your plan accordingly.
- Customer Focus: Scrum focuses on delivering customer value. It frames development work from the lens of the customer and encourages stakeholders to provide constant feedback through practices such as sprint reviews.
- Regularity: Its rigid time boundaries allow teams to get used to flowing through a regular work cadence – something that caters to basic human psychology.
- Autonomy: By providing teams with broad autonomy to self-govern, they are happier, more productive, and more engaged (Pink, 2009) (Sutherland, 2014).
- Improvement through Inspection: Teams constantly inspect themselves, especially during retrospectives at the end of each sprint. Teams improve performance through each development cycle by learning and adapting from the previous cycles.
- Well-known: As the most common agile approach with over 12 million practitioners (Scrum Alliance, 2017), team members or management might already have familiarity and experience with Scrum which eases Scrum adoption.
- Accountability: Individuals feel accountable to their team members. This is reinforced by the transparent nature of Scrum and practices such as the daily standup and sprint reviews where team members are constantly demonstrating their work.
- Sense of Urgency: Because a deadline is always looming, teams are more motivated to deliver. Procrastination will become painfully obvious.
Challenges for using Scrum for Data Science
While Scrum has a lot of benefits for data science, it also presents numerous challenges.
- Time Boxing Challenges: Although it provides numerous benefits, the time boxing feature of Scrum is controversial, especially for data science teams. The time required to implement a solution for most data science problems is ambiguous and depends on unknowns such as data access, questionable data quality, or the untested ability to differentiate signal from noise. Moreover, when pressed to hit the deadline, teams might cut corners which can lead to incomplete testing, rushed analyses, and unnecessary technical debt.
- Cultural Challenges: By upending the traditional hierarchical reporting structure of organizations, Scrum can be unsettling across all levels of the organization (Rigby, Sutherland, & Takeuchi, 2016). Development team members who are used to having their work directed to them might become uncomfortable with self-directed work responsibilities. Previously siloed data scientists might also indirectly oppose the emphasis of teamwork. Management, who traditionally hold much authority over teams might be hesitant to let teams self-manage. Executives might also insist on well-defined, long-term project timelines that are common in other frameworks like Waterfall. These “organizational design and culture” issues are the most commonly stated challenge (52% of respondents) in implementing Scrum (Scrum Alliance, 2017).
- “Definition of Done” Challenges: Scrum prescribes teams to deliver product increments that meet the pre-defined “Definition of Done”. However, Jeff Sutherland, one of the co-founders of Scrum, reports that “80% of the hundreds of Silicon Valley teams I polled could not do this” (Sutherland, 2015). This challenge is particularly daunting for data science teams and might not even be necessary. Indeed, much of the team’s work, especially in the early exploratory phases, may not be intended for release outside the data science team.
- Meeting Overhead: Scrum’s meetings typically require about four hours per week, plus additional time for story refinement and backlog management. At least one project manager we interviewed sees these meetings might be viewed as overhead that should be avoided.
- Difficult to Master: The 2017 Scrum Guide starts out stating that Scrum is “difficult to master”. Survey respondents in the State of Scrum Report would agree. For example, student teams working on a data science project in a controlled experiment who used Scrum performed the worst, largely because of their inability to understand the methodology and to set up clear sprints (Saltz, Shamshurin, & Crowston, 2017).
Recommendations for using Scrum for Data Science
Data science Scrum teams should proactively acknowledge these challenges and devise plans to accommodate Scrum for their needs. Possible solutions include:
- Provide Training: Organizations that implement Scrum should provide extensive training to team members and at least some training to the broader organization. For support, explore the Data Science Team Lead course or our consulting services.
- Prioritize “Spikes”: To allow for research and discovery, teams could create spikes which are items in the backlog that provide research time for intense study on specified topics. These spikes sit along-side product increment ideas in the backlog. They are considered “done” when the specified research objectives are met, or the time limit expires.
- Divide and Conquer: Data scientists often don’t know how much effort a task will require. A possible solution is to divide the work increments into smaller pieces that are definable and estimate-able.
- Shorten Sprints: Similarly, in a one-on-one interview, Daniel Mezick states that “the closer something flirts to chaos, the way to figure out what to do is through frequent inspection.” He recommends using shorter sprint cycles to force these more frequent inspections.
- Occasionally Relax “Definition of Done”: Exploratory work and proofs of concept often don’t need to be fully “done”. Therefore, teams could agree to relax the definition of done for certain stories. However, teams should ensure that they don’t fall down a slippery slope of accepting lower-quality output for core deliverables.
- Renegotiate Work during the Sprint: Contrary to a popular misconception, the sprint plan is not locked in stone at sprint planning. Rather, teams should “negotiate the scope of the Sprint Backlog” when needed (Scrum Guide, 2020).
- Build an “Architectural Runway”: Teams that need a new larger-scale architecture may find careful upfront planning more effective. Diverging from the customer-centric focus of Scrum, data science teams may take a concept from Scaled Agile Framework (SAFe) and dedicate some initial sprints to develop an architecture (Scaled Agile, Inc, 2017).
- Do the Least Understood Work First: Akred recommends teams to “Frontload the parts you don’t understand and then as we get confident in our ability we start building the things around it that actually turn that thing into a usable system” (Akred, 2015). If the team is unable to prove feasibility within a reasonable number of cycles, it can re-focus on other work.
- Integrate with CRISP-DM: To address the data science process, integrate CRISP-DM or another data science life cycle with Scrum to manage data science projects.
- Have a Data Science Scrum Master: This isn’t really optional…and yet is often lacking from data science Scrum teams.
- Consider a Different Approach: Next section…
Agile Alternatives to Scrum
Trying to break free from the time rigidness and other challenges of Scrum, some data science teams have adopted Kanban.
This approach allows teams to relax many of the Scrum practices that might impede progress. However, as a very simple approach, Kanban teams will need to define a lot of additional practices to successfully deliver a project.

Alternatively, Jeff and Alex defined a new framework in 2019 specifically aimed for data science teams.
Data Driven Scrum incorporates some of the key concepts of Scrum, and also addresses the key challenges that arise when using Scrum in a data science context.

Learn More
- Understand the general concept of agile data science
- Learn whether agile is a fit for data science
- Learn how to use agile as a part of an overall data science process
- Get Data Science Team Lead Certified
Become a Data Science Team Lead
The Data Science Team Lead course is the leading agile project management course focused specifically on data science project outcomes.





